Eagle-eyed partners would have spotted the on-prem OCR extension pack on the reseller portal – it comes hot on the heels of the Advanced Print Deploy option.
No need to go into what OCR is, if you are here, we can assume you know!
In version 19 of PaperCut MF, the talented development team introduced a locally hosted (on-premise) OCR option:

With the introduction of On-premise OCR, PaperCut caters for businesses that don’t want documents leaving the internal company infrastructure and as always, it’s super easy to setup. The local OCR option gives you the same functionality as PaperCut’s cloud-hosted scanning service, but all OCR processing is completed on your local server.
It’s a perfect choice if latency and large scan sizes are a problem; and if any of your security policies mean the cloud isn’t for you just yet (and we won’t judge you for that!).
You can activate it once installed across your entire device fleet with one click, and it works with both scan to email and any local folder scan actions. Also, just because we know you would ask, it does indeed use Tesseract as the OCR engine.
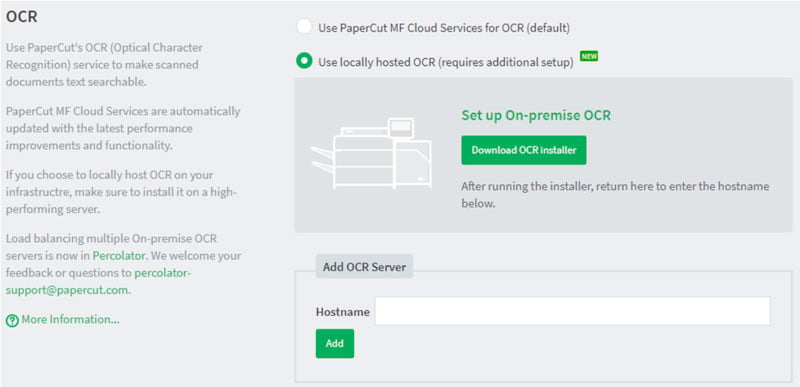
The installation comprises of downloading the application and installing it on the server of your choice. Once you’ve done this, enter the IP address (if the server is running a static IP) or the server’s hostname and click add to finish the setup.
If you run into issues you can check the logs in:[install_path]/data/logs – oh, and you will need to open port 9198 as well (SSL/TLS).
Top Tip: We would not recommend putting the OCR software on the same server running PaperCut MF – OCR can be fairly CPU intensive and it may have a negative impact on other services.
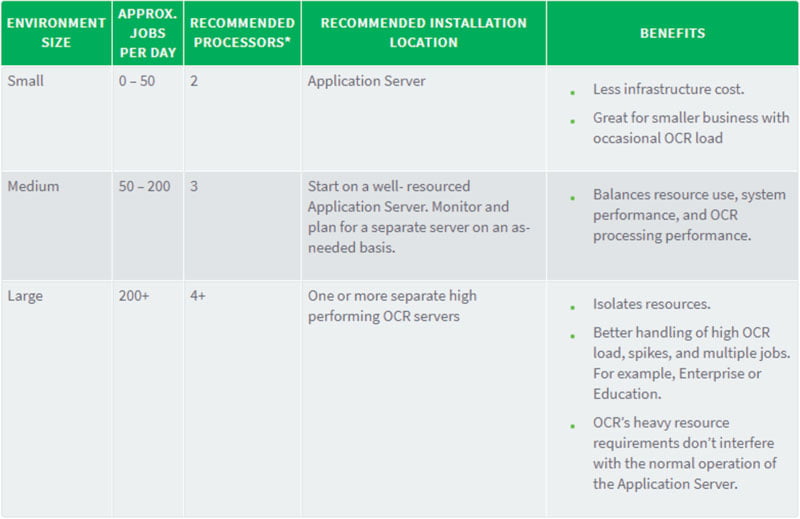
The server specifications for running on-premise OCR are as follows:
Once installed, you can keep an eye on what is happening by going to https://OCRSERVER:9181/api-b/v1/status
The approach to tuning the performance of an OCR server depends on whether it is on a standalone system or co-located with other services.
By default, the OCR server processes two jobs in parallel, and they are processed with a normal CPU priority. You can change the default number of parallel jobs by modifying the configuration file at:
[ocr-server-path]/data/config/config.toml
After making changes to the config file, you’ll need to restart the PaperCut OCR Windows service.
When installing the OCR server on a standalone system, it’s a good idea to maximise the number of jobs that can be processed in parallel to achieve the best performance.
The ideal number depends on many factors, like the type and size of the documents being processed and system architecture. A reasonable starting point is to use the total number of virtual CPUs (or cores x threads on a “bare metal” system), minus two.
Put another way, if you want to process four OCR jobs in parallel and you are installing OCR on a virtual machine, give it six virtual CPUs. To make this change, in the config.toml file remove the # at the start of the MaxJobsInParallel line to uncomment the option and make it active.
Set the MaxJobsInParallel line to MaxJobsInParallel = 4 and as before, restart the PaperCut OCR Windows service.
Lots of scans in a busy system? No worries! The local OCR option supports multiple servers, offering all the good things like scalability, redundancy, performance gains and load balancing.
The gift that keeps on giving; the OCR pack will be expanded in the future to split, compress, despeckle etc. jobs. All that super clever post-processing your customers demand.
Request a trial license below!

With more experience fixing “stuff” than you can shake a stick at, Paul brings his calm and friendly Welsh demeanour to full effect when helping our network of resellers.
 info@selectec.com
info@selectec.com
